“Java面经”的版本间的差异
来自qingwei personal wiki
(创建页面,内容为“== 基础== === interface, abstract class区别 === https://blog.csdn.net/b271737818/article/details/3950245 === string stringbuffer stringbuilder 区别 === ==…”) |
(没有差异)
|
2018年9月19日 (三) 06:55的最新版本
基础
interface, abstract class区别
https://blog.csdn.net/b271737818/article/details/3950245
string stringbuffer stringbuilder 区别
集合
说一下数组和链表的区别?它们分别使用于什么场合?
数组和链表。数组的特点是:寻址容易,插入和删除困难;而链表的特点是:寻址困难,插入和删除容易。
HashMap冲突解决
Java 8 之前:HashMap和其他基于map的类都是通过链地址法解决冲突,它们使用单向链表来存储相同索引值的元素。在最坏的情况下,这种方式会将HashMap的get方法的性能从O(1)降低到O(n)。
Java 8中:为了解决在频繁冲突时hashmap性能降低的问题,Java 8中使用平衡树来替代链表存储冲突的元素。这意味着我们可以将最坏情况下的性能从O(n)提高到O(logn)。
在Java 8中使用常量TREEIFY_THRESHOLD来控制是否切换到平衡树来存储。目前,这个常量值是8,这意味着当有超过8个元素的索引一样时,HashMap会使用树来存储它们。
为什么产生冲突: HashMap中调用hashCode()方法来计算hashCode。 由于在Java中两个不同的对象可能有一样的hashCode,所以不同的键可能有一样hashCode,从而导致冲突的产生。
hashmap put get实现原理(JDK1.8后)
- put
- 对key的hashCode()做hash,然后再计算index; ----! 通过 array大小&hashcode 算出index, get时也是同样==先算hashcode, 有冲突后再equals
- 如果没碰撞直接放到bucket里;
- 如果碰撞了,以链表的形式存在buckets后;
- 如果碰撞导致链表过长(大于等于TREEIFY_THRESHOLD),就把链表转换成红黑树;
- 如果节点已经存在就替换old value(保证key的唯一性)
- 如果bucket满了(超过load factor*current capacity),就要resize。
- get
- bucket里的第一个节点,直接命中;
- 如果有冲突,则通过key.equals(k)去查找对应的entry
- 若为树,则在树中通过key.equals(k)查找,O(logn);
- 若为链表,则在链表中通过key.equals(k)查找,O(n)。
- put
public V put(K key, V value) {
// 对key的hashCode()做hash
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// tab为空则创建
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 计算index,并对null做处理
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// 节点存在
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 该链为树
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 该链为链表
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 写入
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 超过load factor*current capacity,resize
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
- get
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 直接命中
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 未命中
if ((e = first.next) != null) {
// 在树中get
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 在链表中get
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
线程
HashMap是不是线程安全?为什么非线程安全或者说哪里体现了非线程安全?HashMap的读写线程安全吗?
那如何实现线程安全呢?Hashtable和ConcurrentHashMap实现方式?
synchronized锁实现原理?
实现线程安全的方式有哪些?并介绍一下实现?
了解线程池不?线程池的基本参数有哪些?
线程池是解决什么问题的?
spring框架
spring ioc是什么?实现了什么之间的反转?
spring aop 原理
spring, spring-boot, spring-cloud区别
spring-boot boot-starter了解吗
JVM
jvm内存模型
运行时内存模型:分为线程私有和共享数据区两大类
- 线程私有的数据区:程序计数器、虚拟机栈、本地方法区
- 所有线程共享的数据区:Java堆、方法区,在方法区内有一个常量池。
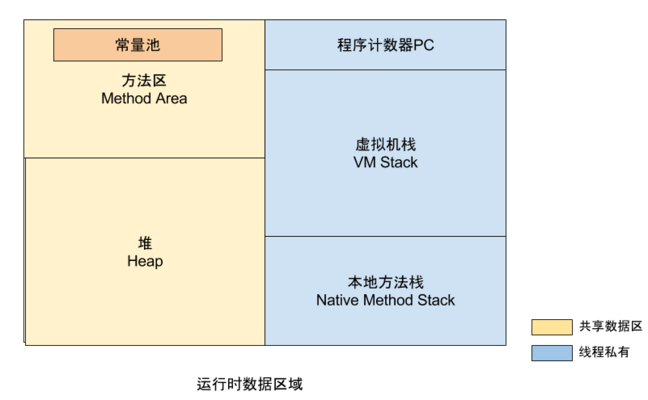
运行时内存模型

gc算法
数据库
三范式
- 第一范式:要求有主键,并且要求每一个字段原子性不可再分
- 第二范式:要求所有非主键字段完全依赖主键,不能产生部分依赖
- 第三范式:所有非主键字段和主键字段之间不能产生传递依赖
左连接,右连接
事务隔离级别
✔️表示会发生, ❌表示不会发生
| 隔离级别 | 脏读(Dirty Read) | 不可重复读(NonRepeatable Read) | 幻读(Phantom Read) |
|---|---|---|---|
| 未提交读(Read uncommitted) | ✔️ | ✔️ | ✔️ |
| 已提交读(Read committed) | ❌ | ✔️ | ✔️ |
| 可重复读(Repeatable read) | ❌ | ❌ | ✔️ |
| 可串行化(Serializable) | ❌ | ❌ | ❌ |
- 未提交读(Read Uncommitted): 一个事务可以读取到另一个事务未提交的修改。
- 提交读(Read Committed): 一个事务只能读取另一个事务已经提交的修改。
- 可重复读(Repeated Read): 同一个事务中多次读取相同的数据返回的结果是一样的。因为:在事务执行期间会锁定该事务以任何方式引用的所有行。这是MySQL中InnoDB默认的隔离级别。
- 可串行化(Serializable): 事务串行执行。每次读都需要获得表级共享锁,读写相互都会阻塞
- 不可重复读和幻读的区别
如果使用锁机制来实现这两种隔离级别,在可重复读中,该sql第一次读取到数据后,就将这些数据加锁,其它事务无法修改这些数据,就可以实现可重复读了。但这种方法却无法锁住insert的数据,所以当事务A先前读取了数据,或者修改了全部数据,事务B还是可以insert数据提交,这时事务A就会发现莫名其妙多了一条之前没有的数据,这就是幻读,不能通过行锁来避免。需要Serializable隔离级别 ,读用读锁,写用写锁,读锁和写锁互斥,这么做可以有效的避免幻读、不可重复读、脏读等问题,但会极大的降低数据库的并发能力。 所以说不可重复读和幻读最大的区别,就在于如何通过锁机制来解决他们产生的问题。 MySQL、ORACLE、PostgreSQL等成熟的数据库,出于性能考虑,都是使用了以乐观锁为理论基础的MVCC(多版本并发控制)来避免这两种问题。
在(A, B)上创建索引,select B时这个索引有用吗,为什么
最左原则
分布式事务(DTS)
算法
快排
swap(a, b) 深究 值拷贝,引用传递
public class Main {
// 反射
public void swap(Integer a, Integer b) {
int temp = a;
try {
Class clazz = a.getClass();
Field value = clazz.getDeclaredField("value");
value.setAccessible(true);
value.setInt(a, b);
value.setInt(b, temp);
} catch (Exception ex) {
ex.printStackTrace();
}
}
public static void main(String[] args) {
Main main = new Main();
/* Integer 换成 int a = 1, 不行!!!*/
Integer a = 1;
Integer b = 2;
main.swap(a, b);
System.out.println("a = " + a + ", b= " + b);
}
}